

Naja. Wenn du freundlich bist und angespuckt wirst, weißt du selbst aber wenigstens, dass du alles richtig gemacht hast und nichts dafür kannst. Bist du unfreundlich und wirst angespuckt, bist du selbst schuld. Da du jetzt auch nicht wie so ein Ghetto-Assi-Kind auf mich wirkst, glaube ich, du würdest mit Freundlichkeit deutlich besser fahren. Wenn du nämlich dann Stress mit jemandem hier hast, gibt es einen Haufen Leute, die dir helfen können und wollen. Wenn du selbst oft der Provokateur bist, sehen die Leute keinen Sinn darin, dich zu unterstützen und schießen erst recht gegen dich.
Beiträge von Ternary
-
-
Mein Interesse, jetzt deine Beiträge zu durchforsten, hält sich in Grenzen. Aber man sieht oft genug, wie du dich an Streitereien und ähnlichen beteiligt - und das nicht gerade deeskalierend. Wenn ich deinen Namen irgendwo sehe, erwarte ich jedenfalls schon beinahe entsprechendes.
Ich habe ja nicht geschrieben, dass du hier ständig Beef anfängst. Aber wenn mal irgendwo Zoff ist, bist du meist auch nicht weit. -
Im "das Maul aufreißen" bist du aber auch sehr fleißig. Zumindest machst du das erstaunlich oft und nicht selten auf einem Niveau, bei dem es vollkommen offensichtlich ist, dass du provozieren möchtest. Wie du es schaffst, dabei noch ohne Bann weg zu kommen, erstaunt mich immer wieder - meinen Respekt hast du dafür.
Vor fünf Jahren jedenfalls hättest du hier mit dem Verhalten keine lange Karriere gehabt. Heute ist das Team da wohl um einiges lockerer. -
Wenn du noch nie mit Git entwickelt hast, wäre diese Info noch ganz hilfreich: denk daran, dass du dafür seinen Workflow ändern musst. Und zwar ein gutes Stück. Du musst ja schließlich auch die Quellcodeverwaltung verwalten und ordentlich committen. Sonst ist das alles witzlos.

Für mich sieht das weniger aus wie ein build-server, sondern eher das die letzten commitments gepusht wurden ins repo.
Sieht eher nach einer CI aus, die Builds nach jedem Commit triggert.
-

Wer einen XAMPP Server für einen Liveserver nutzt, hat sie nicht mehr alle.
Warum denn das? XAMMP ist auch nur ein Software Bundle, das die wichtigsten Anwendungen für die Bereitstellung von Webservices bereit stellt.
-

Du hast vier verschiedene Lösungsansätze hier im Thread, die alle zu dem führen, was du wolltest. "Nicht möglich" trifft es da nicht ganz.
Hast du denn einen davon mal ausprobiert?Jein, bei PVars ist das zum Beispiel nicht notwendig. Diese können frei gefüllt verwendet werden.So könnte man beispielsweise Items zur Laufzeit aufnehmen, ohne den Code zu verändern.
PVars sind keine Variablen in dem Sinn. PVars sind einfach nur Wrapper für Mappings, die im Hintergrund letztlich in diversen Arrays abgelegt werden. Das macht das ganze aber nicht nur langsamer sondern erzeugt bei gleicher Nutzdatenmenge auch noch einen ordentlichen Overhead. Mit Variablen ist das nicht zu verwechseln. Die müssen nach wie vor bereits zur Kompilierzeit bekannt sein.
-
Indize sind nun mal keine Strings. An diesem Grundsatz wirst du in Pawn nicht vorbei kommen. Ohnehin ist es unsinnig, einfach ungeprüft irgendwelche Strings als Index zu nehmen. Nachher ist da ein ungültiges Zeichen drin und dir schmiert mindestens mal die Funktion, wenn nicht sogar das ganze Script ab.
Aber es geht ja ohnehin nicht. Pawn wird ja bekanntlich kompiliert und alle Variablen und Indize müssen zur kompilierzeit bekannt sein. -
Also, wenn du in der tabB nur die Nutzer-ID stehen hast, ist der performanteste Weg immer, erst die Nutzer-ID im Programmablauf herauszufinden und dann eben auf die ID zu suchen.
Notfalls geht auch das hier:SQLSELECT tabA.id, COALESCE(tabB.farbe, tabA.farbe) AS farbe, COALESCE(tabB.preis, tabA.preis) AS preis FROM tabA LEFT JOIN tabB ON tabB.id = tabA.id AND (SELECT tabC.name FROM tabC WHERE tabC.id = tabB.userid) = 'Test'Das Subselect ist aber halt inperformant, weil du an jeden einzelnen Eintrag in tabB noch die UserID matchen musst. Wenn du die vorher schon kennst, kannst du dir das halt sparen.
-

Es gibt noch eine weitere Tabelle User & jedesmal wenn ich diese mit eingebunden habe, wurden nur noch Daten angezeigt, bei welchem der Benutzer Eingaben gemacht hatte.
@SynonymousZ
Schaue ich mir später mal an, bin gerade Mobil unterwegs. Leider besteht aber keine Option die bestehenden Tabellen anzupassen.Kannst du mir das Schema dieser Tabelle geben? Dann finden wir da sicher ne Lösung.
-
So hatte ich es schon, folgte aber nicht zum richtigen Ergebnis. Problem entstand hiermit beim einbeziehen der Benutzerid, da dann nur Ergebnisse angezeigt wurden bei welchen diese existierte.
Hab ich was falsch verstanden? So wie ich das verstanden hatte, willst du doch sowas hier, oder nicht?
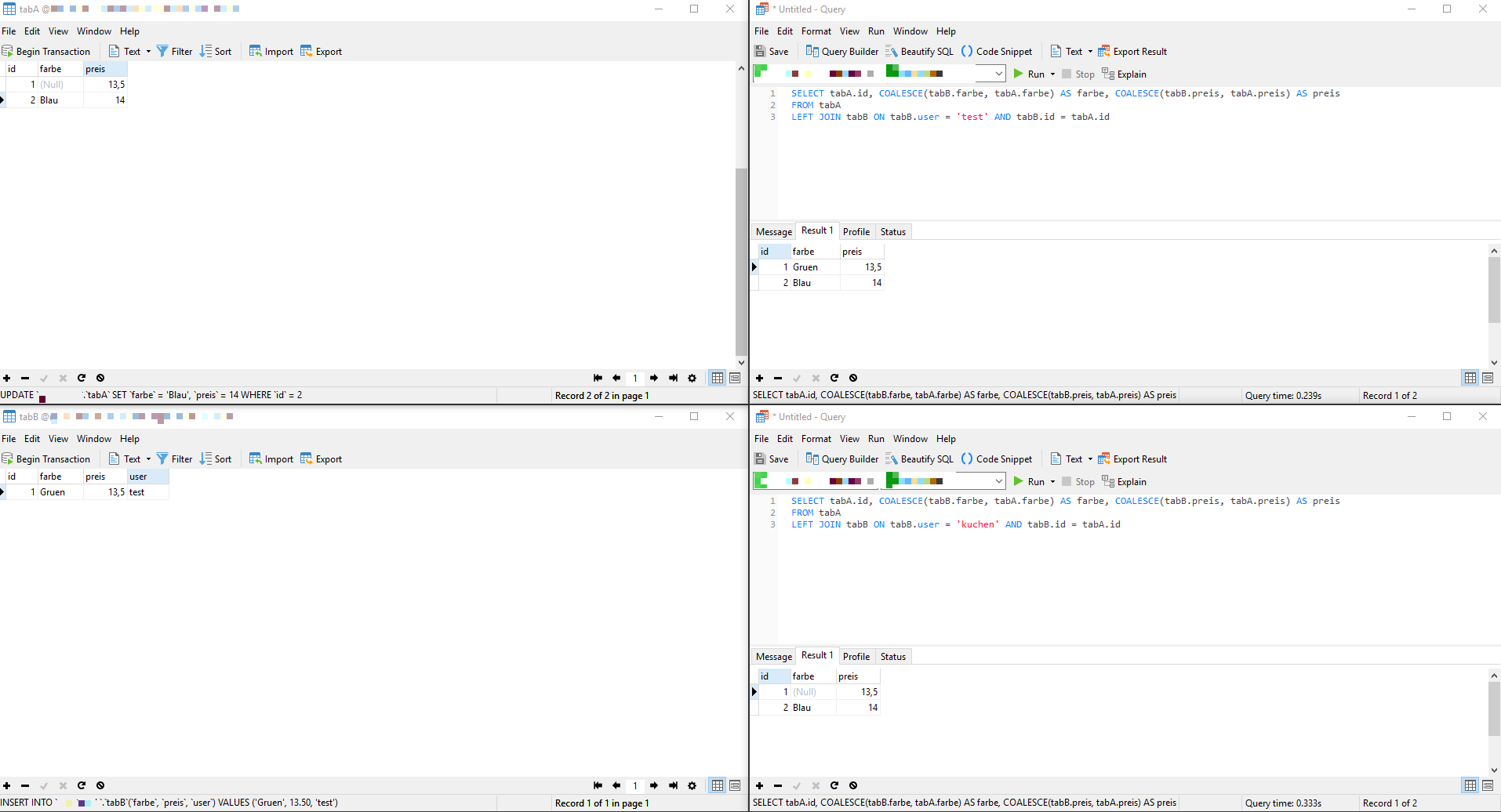
-
UNION ist ja nicht in der Lage, die Tabellen logisch zu verknüpfen und wäre hier eigentlich nicht dienlich. Mein erster Gedanke wäre die Tabelle B an Tabelle A LEFT JOINen und dann mittels COALESCE erst die Einträge aus B und wenn diese NULL sind eben die aus A zu nehmen. Kann später, wenn ich am PC bin mal ein Beispiel schreiben.
/edit:
So in etwa machen wir das auf der Arbeit, wenn wir potentiell invalide Dimensionen ranmatchen und im Falle einer fehlenden Referenz den Ursprungswert beibehalten wollen.SQLSELECT tabA.id, COALESCE(tabB.farbe, tabA.farbe), COALESCE(tabB.preis, tabA.preis) FROM tabA LEFT JOIN tabB ON tabB.user = 'test' AND tabB.id = tabA.idWir haben auf der Arbeit nur Microsoft SQL, sollte aber auch in MySQL funktionieren. Dadurch, dass du im Endeffekt nur den einen Join hast, bist du so performant unterwegs, wie es geht.
-
Das wird der Mapper, der seit einem halben Jahr nicht mehr hier war, sicher beherzigen

-
DHL an sich ist ja einfach nur eine Firmengruppe oder Marke. Für die kleinen Pakete ist DHL Express zuständig. Das ist das was gemeinhin unter DHL mit dem DHL Boten verstanden wird. Es gibt aber auch noch DHL Freight. Das ist für den richtig großen Stuff. Darüber kannste auch gegen entsprechende Bezahlung ein ganzes Auto verschicken. Demnach würde ich sagen: DHL ist die Spedition.
-
Heute kam mein AP heil und unbeschadet ab. Lief alles unkompliziert: von der Zahlung bis zum Versand. Konnte ihn leider noch nicht in Betrieb nehmen, sieht aber von außen vollkommen in Ordnung an (Gebrauchsspuren sind obligatorisch). Außerdem bietet Chromer auch Hilfe bei der Einrichtung an, was vielleicht gerade für diejenigen, die nicht so viel Ahnung haben, eine Erleichterung sein könnte.
-
Android verwendet schon seit einigen Versionen die API von OpenJDK. Da muss überhaupt nichts mehr entfernt werden. Es geht bei dem Rechtsstreit eigentlich nur noch um den Schadensersatz für die älteren Versionen sowie ein Stück weit ums Prinzip. Kotlin hin oder her: Java wird noch für viele Jahre die bevorzugte Sprache zur Entwicklung nativer Android Apps bleiben. Da wirst du gerade als Einsteiger auch mit Abstand den meisten Support und am ehesten Hilfe erhalten.
-
Hi Individuum,
wenn noch Kapazität für einen Container übrig wäre, hätte ich auch durchaus Interesse daran. Einfach Ubuntu 16.04 drauf und ich bin glücklich
Viele Grüße
Ben -
Mit dem setup kostet dich in Deutschland der Strom mehr, als dir das Mining einbringt.
-
Gut. Rechnung kommt dann.
-
Ich klinke mich mal ein weil ich in der Arbeit ein Verwaltungsprogramm von Windows 2000 in eine Weboberfläche umheben muss. Welche PHP Funktion sollte man da jetzt nehmen? Im Internet finde ich da z.B die crypt() Funktion, die ziemlich "neu" sein soll. Damit kann man dann ja den Algor. auch auswählen, oder?
Kannst du. Zumindest für Passwörter bietet sich aber wie bereits erwähnt password_hash() und password_verify() an. Das sind letztlich einfach nur Wrapper um die crypt() Funktion, die dir ein bisschen Arbeit bei der Verifikation abnehmen aber vor allem (also bei _hash) sicherstellen, dass du einen ordentlichen Salt und einen angemessenen Algorithmus hast. Das ist also letztlich der Idiotensichere Weg. Mit crypt() selbst kannst du halt bei Bedarf so lustigen (aber faktisch unnötigen) Kram wie Double-Salts umsetzen. Ich würde dir da einfach die PHP Dokumentation zu den Funktionen ans Herz legen. Die sind vergleichsweise ausführlich. Vor allem gibt es da in den "User Kommentaren" oft noch ein paar best practices.
-

@42656e
Jo, aber wenn er eine TOP 5 o.ä. erstellen will, ist das am einfachsten.Und wir reden hier von einem n mit einem Wert von 20-50. Das nimmt sich auf dem kleinen Zahlenraum nichts und ist einfacher zu nutzen, als jetzt 5 Variablen da durchlaufen zu lassen und einen komplexeren Algorithmus zu schreiben.
Das stimmt natürlich. Aber zumindest als ich den Beitrag noch lesen konnte, ging es erst mal nur um den Maximalwert.
Und dann geht es letztlich einfach ums Prinzip. Der Junge ist ja offensichtlich noch nicht so super erfahren und will ja vielleicht auch was lernen. Und gerade bei Anfängern und vor allem auch hier in dem Umfeld fällt mir auf, dass Performance einfach keine Sau interessiert. Und das halte ich für fatal. Ich kenne den Typen jetzt nicht und das ist natürlich alles rein spekulativ, aber jetzt stell dir mal vor, der wird irgendwann mal in einem Unternehmen eine Ausbildung in Richtung Data Science machen und fängt dann da an, über Milliarden von Datensätzen zu sortieren, nur um den Maximalwert zu erlangen Habe ich so tatsächlich schon erlebt. Verstehste, was ich meine? Man sollte einfach so früh wie möglich anfangen, auch über Effizienz und Sinnhaftigkeit nachzudenken. Selbst wenn man jetzt kein beruflicher Entwickler oder Data Analyst wird, schadet es einem im Leben und Beruf nicht, solche Denkmuster verinnerlicht zu haben.Mal ganz abgesehen davon, dass das ja jetzt kein komplizierter Algorithmus ist. Im Gegenteil dazu ist Quicksort ja schon Rocket Science. Und da hätte er dann einfach nur irgendeinen Code Schnipsel kopiert, den er nicht mal versteht.
Es führen immer viele Wege nach Rom. Aber mir persönlich ist es wichtiger, dass jemand verstanden hat, was er da macht, warum er es macht und warum er es nicht anders machen sollte. Zu Quick & Dirty Solutions wird man im Leben noch oft genug gezwungen. Ich glaube, auf dieses Ziel zahlt mein Input durchaus ein.